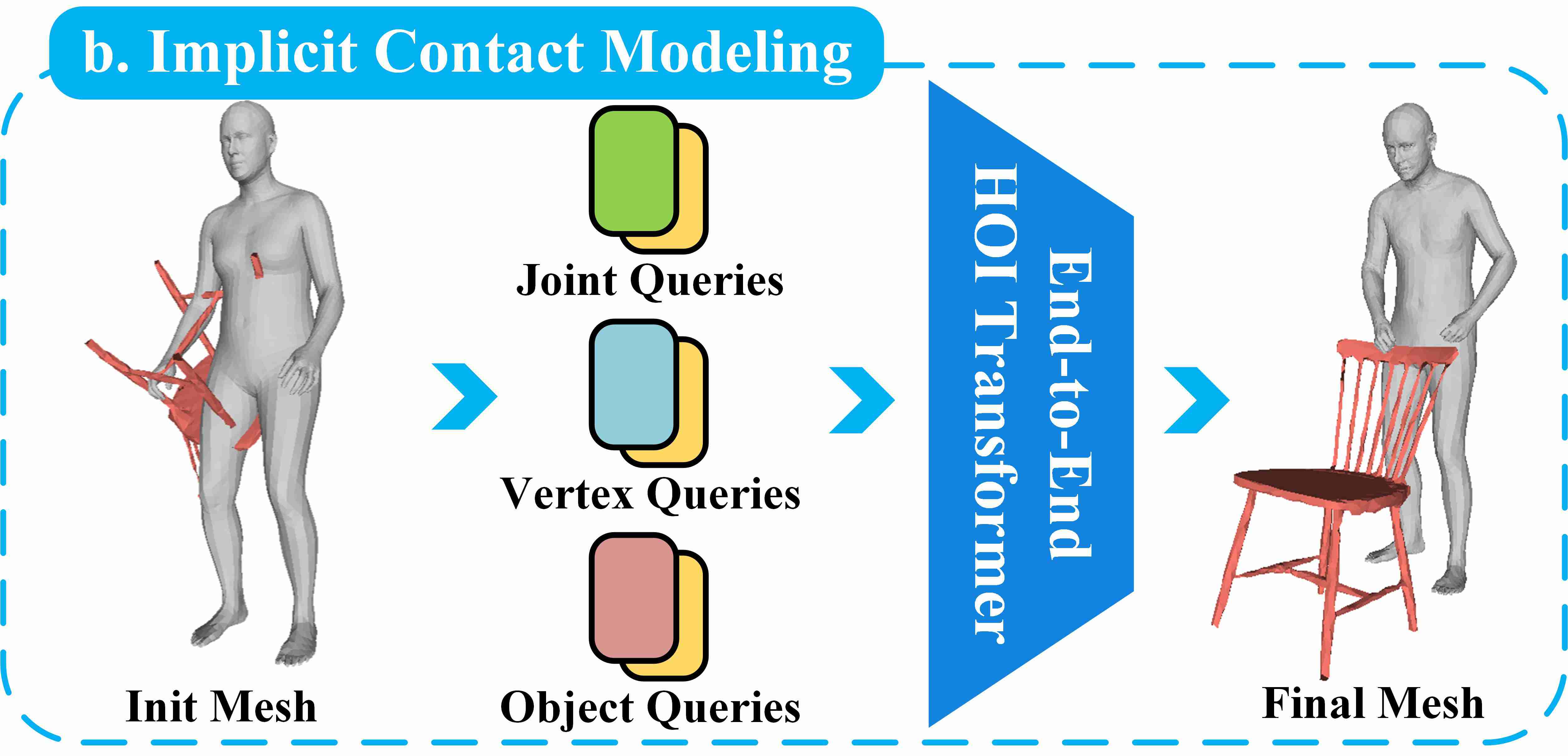
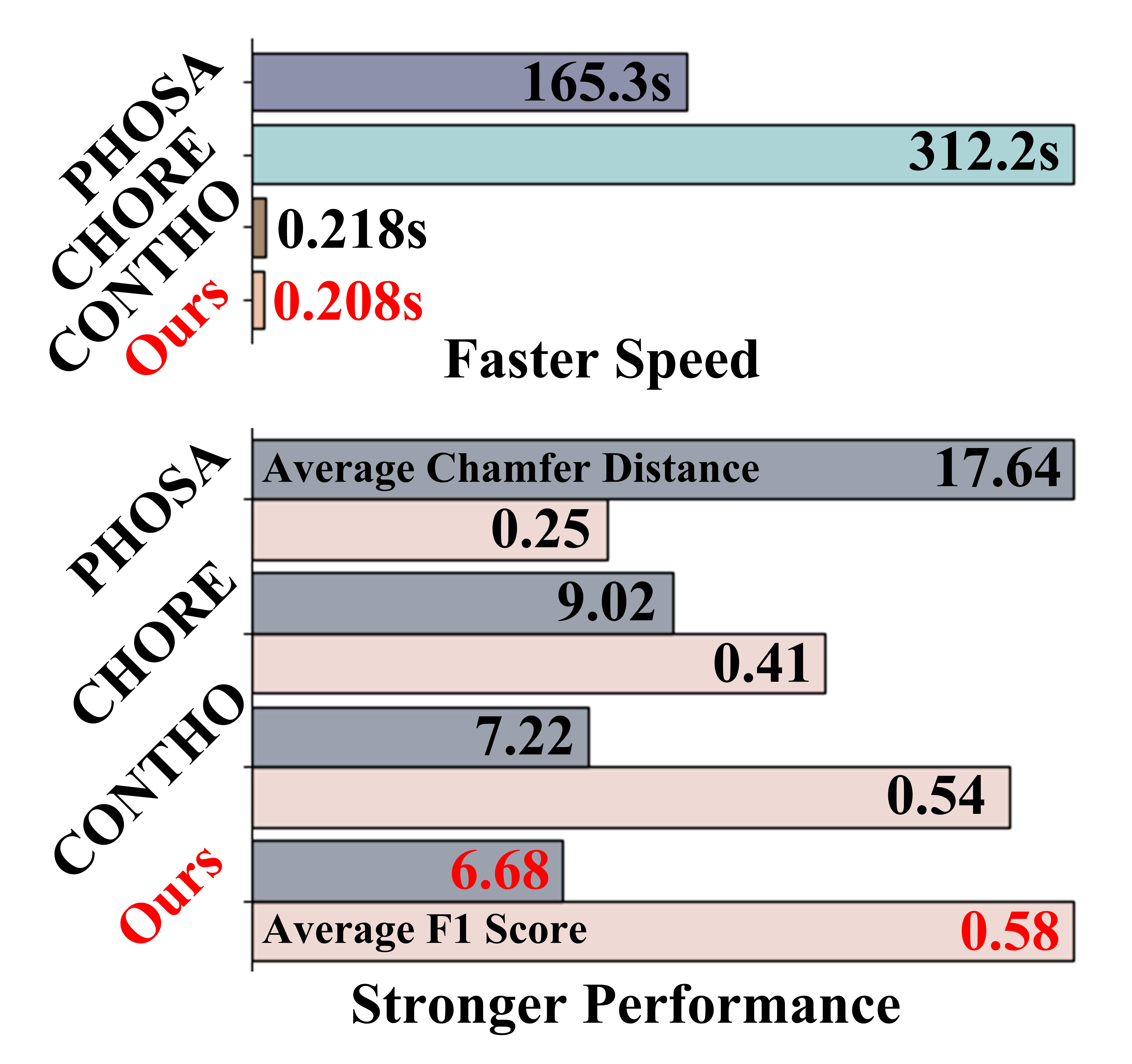
HOI-TG is an end-to-end transformer framework for 3D human-object interaction (HOI) reconstruction from a single image. It innovatively utilizes self-attention to implicitly model the contact between humans and objects. The model achieves state-of-the-art performance on the BEHAVE and InterCap datasets, improving human and object reconstruction accuracy by 8.9% and 8.6% on InterCap, respectively. This demonstrates the robust integration of global posture and fine-grained interaction modeling without explicit constraints.